Tute 2 Answers
1. What is the need for VCS?
Version control systems are a category of software tools that help a software team manage changes to source code over time. Version control software keeps track of every modification to the code in a special kind of database. If a mistake is made, developers can turn back the clock and compare earlier versions of the code to help fix the mistake while minimizing disruption to all team members.
For almost all software projects, the source code is like the crown jewels - a precious asset whose value must be protected. For most software teams, the source code is a repository of the invaluable knowledge and understanding about the problem domain that the developers have collected and refined through careful effort. Version control protects source code from both catastrophe and the casual degradation of human error and unintended consequences.
Software developers working in teams are continually writing new source code and changing existing source code. The code for a project, app or software component is typically organized in a folder structure or "file tree". One developer on the team may be working on a new feature while another developer fixes an unrelated bug by changing code, each developer may make their changes in several parts of the file tree.
Version control helps teams solve these kinds of problems, tracking every individual change by each contributor and helping prevent concurrent work from conflicting. Changes made in one part of the software can be incompatible with those made by another developer working at the same time. This problem should be discovered and solved in an orderly manner without blocking the work of the rest of the team. Further, in all software development, any change can introduce new bugs on its own and new software can't be trusted until it's tested. So testing and development proceed together until a new version is ready.
Good version control software supports a developer's preferred workflow without imposing one particular way of working. Ideally it also works on any platform, rather than dictate what operating system or tool chain developers must use. Great version control systems facilitate a smooth and continuous flow of changes to the code rather than the frustrating and clumsy mechanism of file locking - giving the green light to one developer at the expense of blocking the progress of others.
Software teams that do not use any form of version control often run into problems like not knowing which changes that have been made are available to users or the creation of incompatible changes between two unrelated pieces of work that must then be painstakingly untangled and reworked. If you're a developer who has never used version control you may have added versions to your files, perhaps with suffixes like "final" or "latest" and then had to later deal with a new final version. Perhaps you've commented out code blocks because you want to disable certain functionality without deleting the code, fearing that there may be a use for it later. Version control is a way out of these problems.
Version control software is an essential part of the every-day of the modern software team's professional practices. Individual software developers who are accustomed to working with a capable version control system in their teams typically recognize the incredible value version control also gives them even on small solo projects. Once accustomed to the powerful benefits of version control systems, many developers wouldn't consider working without it even for non-software projects.
2. Differentiate the three models of VCSs, stating their pros and cons
- Local Data Model: This is the simplest variations of version control, and it requires that all developers have access to the same file system.
- Client-Server Model: Using this model, developers use a single shared repository of files. It does require that all developers have access to the repository via the internet of a local network. This is the model used by Subversion (SVN).
- Distributed Model: In this model, each developer works directly with their own local repository, and changes are shared between repositories as a separate step. This is the model used by Git, an open source software used by many of the largest software development projects.

3. Git and GitHub, are they same or different? Discuss with facts.

4. Compare and contrast the Git commands, commit and push
git commit: Add a new commit (last commit + staged modifications) to the local repository.git push, git pull: Sync a local repository with its associated remote repository. push - apply changes from local into remote, pull - apply changes from remote into local.
5. Discuss the use of staging area and Git directory
There are three areas where file changes can reside from git’s point of view: working directory, staging area, and the repository.

6. Explain the collaboration workflow of Git, with example
In contrast with Centralized Version Control Systems (CVCSs), the distributed nature of Git allows you to be far more flexible in how developers collaborate on projects. In centralized systems, every developer is a node working more or less equally with a central hub. In Git, however, every developer is potentially both a node and a hub; that is, every developer can both contribute code to other repositories and maintain a public repository on which others can base their work and which they can contribute to. This presents a vast range of workflow possibilities for your project and/or your team, so we’ll cover a few common paradigms that take advantage of this flexibility. We’ll go over the strengths and possible weaknesses of each design; you can choose a single one to use, or you can mix and match features from each.
Centralized Workflow
In centralized systems, there is generally a single collaboration model — the centralized workflow. One central hub, or repository, can accept code, and everyone synchronizes their work with it. A number of developers are nodes — consumers of that hub — and synchronize with that centralized location.
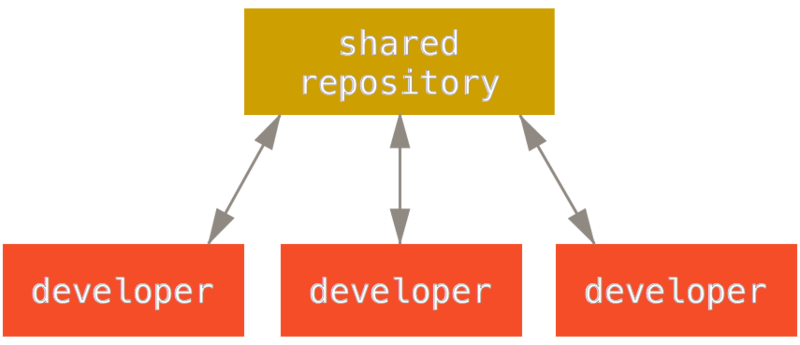
Figure 54. Centralized workflow.
This means that if two developers clone from the hub and both make changes, the first developer to push their changes back up can do so with no problems. The second developer must merge in the first one’s work before pushing changes up, so as not to overwrite the first developer’s changes. This concept is as true in Git as it is in Subversion (or any CVCS), and this model works perfectly well in Git.
If you are already comfortable with a centralized workflow in your company or team, you can easily continue using that workflow with Git. Simply set up a single repository, and give everyone on your team push access; Git won’t let users overwrite each other.
Say John and Jessica both start working at the same time. John finishes his change and pushes it to the server. Then Jessica tries to push her changes, but the server rejects them. She is told that she’s trying to push non-fast-forward changes and that she won’t be able to do so until she fetches and merges. This workflow is attractive to a lot of people because it’s a paradigm that many are familiar and comfortable with.
This is also not limited to small teams. With Git’s branching model, it’s possible for hundreds of developers to successfully work on a single project through dozens of branches simultaneously.
Integration-Manager Workflow
Because Git allows you to have multiple remote repositories, it’s possible to have a workflow where each developer has write access to their own public repository and read access to everyone else’s. This scenario often includes a canonical repository that represents the “official” project. To contribute to that project, you create your own public clone of the project and push your changes to it. Then, you can send a request to the maintainer of the main project to pull in your changes. The maintainer can then add your repository as a remote, test your changes locally, merge them into their branch, and push back to their repository. The process works as follows (see Integration-manager workflow.):
- The project maintainer pushes to their public repository.
- A contributor clones that repository and makes changes.
- The contributor pushes to their own public copy.
- The contributor sends the maintainer an email asking them to pull changes.
- The maintainer adds the contributor’s repository as a remote and merges locally.
- The maintainer pushes merged changes to the main repository.
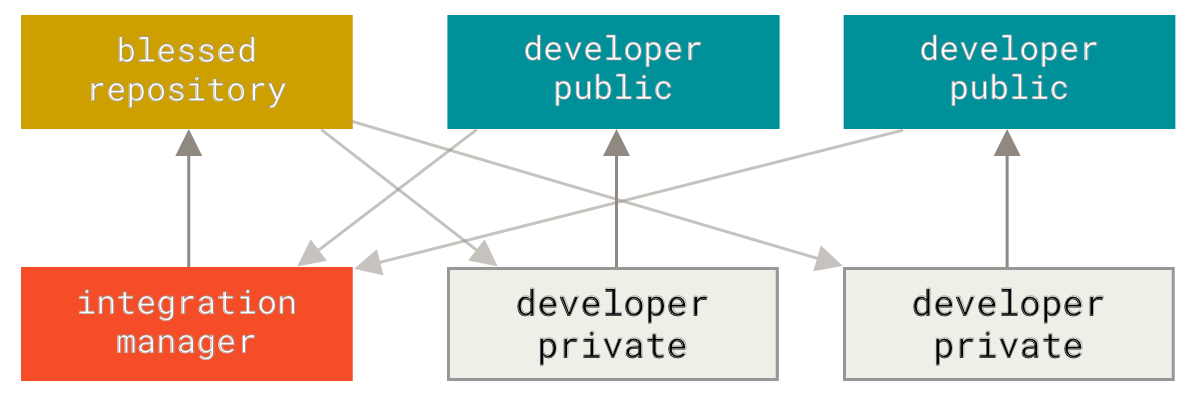
Figure 55. Integration-manager workflow.
This is a very common workflow with hub-based tools like GitHub or GitLab, where it’s easy to fork a project and push your changes into your fork for everyone to see. One of the main advantages of this approach is that you can continue to work, and the maintainer of the main repository can pull in your changes at any time. Contributors don’t have to wait for the project to incorporate their changes — each party can work at their own pace.
Dictator and Lieutenants Workflow
This is a variant of a multiple-repository workflow. It’s generally used by huge projects with hundreds of collaborators; one famous example is the Linux kernel. Various integration managers are in charge of certain parts of the repository; they’re called lieutenants. All the lieutenants have one integration manager known as the benevolent dictator. The benevolent dictator pushes from his directory to a reference repository from which all the collaborators need to pull. The process works like this (see Benevolent dictator workflow.):
- Regular developers work on their topic branch and rebase their work on top of
master. Themasterbranch is that of the reference repository to which the dictator pushes. - Lieutenants merge the developers' topic branches into their
masterbranch. - The dictator merges the lieutenants'
masterbranches into the dictator’smasterbranch. - Finally, the dictator pushes that
masterbranch to the reference repository so the other developers can rebase on it.
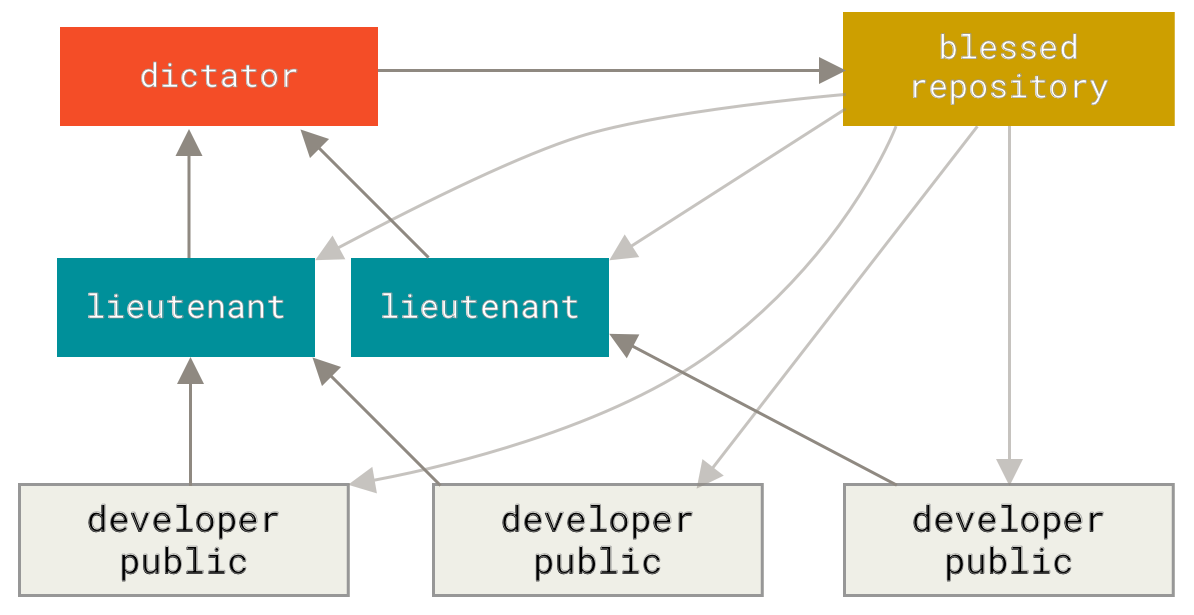
Figure 56. Benevolent dictator workflow.
This kind of workflow isn’t common, but can be useful in very big projects, or in highly hierarchical environments. It allows the project leader (the dictator) to delegate much of the work and collect large subsets of code at multiple points before integrating them.
7. Discuss the benefits of CDNs
Content Delivery Networks (CDN) accounts for large share of delivering content across websites users and networks across the globe. The content found in the websites of today contain a variety of formats such as text, scripts, documents, images, software, media files, live streaming media and on-demand streaming media and so on. In order to deliver such diverse content to users across the globe efficiently, CDNs are deployed in datacenters. CDNs accelerate website performance and provide a numerous benefits for users and also for the network infrastructure.
The internet is a collection of numerous networks or datacenters. The growth of the world-wide-web and related technologies along with proliferation of wireless technologies, cloud computing, etc. is leveraging users to access the internet with multiple devices in addition to computers. Web servers deployed in networks on the internet cater to most of the user requests on the internet. But, when web servers are located in one single location it becomes increasingly difficult to handle multiple workloads. This has an effect on website performance and efficiency is reduced significantly. Further, users access a variety of applications such as interactive multimedia apps, streaming audio and video along with static and dynamic web pages across millions of websites which require efficient and robust network infrastructures and systems. In order to balance the load on infrastructures and to provide content quickly to end users CDNs are deployed in data centers.
Content Delivery Networks (CDN) is a system of servers deployed in different geographical locations to handle increased traffic loads and reduce the time of content delivery for the user from servers. The main objective of CDN is to deliver content at top speed to users in different geographic locations and this is done by a process of replication. CDNs provide web content services by duplicating content from other servers and directing it to users from the nearest data center. The shortest possible route between a user and the web server is determined by the CDN based on factors such as speed, latency, proximity, availability and so on. CDNs are deployed in data centers to handle challenges with user requests and content routing.
CDNs are used extensively by social networks, media and entertainment websites, e-commerce websites, educational institutions, etc. to serve content quickly to users in different locations. Organizations by implementing CDN solutions stand to gain in many ways that include,
- Faster content load / response time in delivering content to end users.
- Availability and scalability, because CDNs can be integrated with cloud models
- Redundancy in content, thus minimizing errors and there is no need for additional expensive hardware
- Enhanced user experience with CDNs as they can handle peak time loads
- Data integrity and privacy concerns are addressed
The benefits of CDNs are more emphasized by examining its usage in a few real time application areas. Some common application areas include,
- E-Commerce: E-commerce companies make use of CDNs to improve their site performance and making their products available online. According to Computer World, CDN provides 100% uptime of e-commerce sites and this leads to improved global website performance. With continuous uptime companies are able to retain existing customers, leverage new customers with their products and explore new markets, to maximize their business outcomes.
- Media and Advertising: In media, CDNs enhance the performance of streaming content to a large degree by delivering latest content to end users quickly. We can easily see today, there is a growing demand for online video, and real time audio/video and other media streaming applications. This demand is leveraged by media, advertising and digital content service providers by delivering high quality content efficiently for users. CDNs accelerate streaming media content such as breaking news, movies, music, online games and multimedia games in different formats. The content is made available from the datacenter which is nearest to users’ location.
- Business Websites: CDNs accelerate the interaction between users and websites, this acceleration is highly essential for corporate businesses. In websites speed is one important metric and a ranking factor. If a user is far away from a website the web pages will load slowly. Content delivery networks overcome this problem by sending requested content to the user from the nearest server in CDN to give the best possible load times, thus speeding the delivery process.
- Education: In the area of online education CDNs offer many advantages. Many educational institutes offer online courses that require streaming video/audio lectures, presentations, images and distribution systems. In online courses students from around the world can participate in the same course. CDN ensures that when a student logs into a course, the content is served from the nearest datacenter to the student’s location. CDNs support educational institutes by steering content to regions where most of the students reside.
In the internet, closer is always better to overcome problems in latency and performance, CDNs are seen as an ideal solution in such situations. Since CDNs share digital assets between nodes and servers in different geographical locations, this significantly improves client response times for content delivery. CDN nodes or servers deployed at multiple locations in data centers also take care of optimizing the delivery process with users. However, the CDN services and the cost are worked out in SLAs with the data center service provider.
8. How CDNs differ from web hosting servers?
- Web Hosting is used to host your website on a server and let users access it over the internet. A content delivery network is about speeding up the access/delivery of your website’s assets to those users.
- Traditional web hosting would deliver 100% of your content to the user. If they are located across the world, the user still must wait for the data to be retrieved from where your web server is located. A CDN takes a majority of your static and dynamic content and serves it from across the globe, decreasing download times. Most times, the closer the CDN server is to the web visitor, the faster assets will load for them.
- Web Hosting normally refers to one server. A content delivery network refers to a global network of edge servers which distributes your content from a multi-host environment.
9. Identify free and commercial CDNs
Free content delivery networks include Coral Content Distribution Network, FreeCast, CloudFare and Incapsula. Popular commercial content delivery networks include the following companies:
10. Discuss the requirements for virtualization
CPU
The three elements to consider when selecting virtualization hardware include the CPU, memory, and network I/O capacity. They're all critical for workload consolidation.
Issues with the CPU pertain to either clock speed or the number of cores held by the CPU. Please don't run out and buy the market's fastest CPU. Instead, buy one with more modest clock speed and a greater number of cores.
You'll receive better consolidation from two CPUs with 2.4 GHz and 10 cores than you will from two CPUs with 3 GHz and 4 cores. Invest in faster CPUs only when your workload demands it. The best server for virtualization will include CPUs with large internal caches.
Memory
Your virtual machine resides in memory. The more memory you have, the greater your consolidation. You need at least enough DDR3 memory to support the number of workloads you run on the system.
Take the 10-core example above. The two 10 core CPUs would support 40 threads of potential workloads. We derive this number from adding the number of cores (20 total). Then we multiply the result by 2 because each core has two threads.
If each workload uses 2 GB, your server would need at least 80 GB. The closest binary equivalent would be either 96 GB. Anything less would compromise your consolidation or your performance.
Anything more would just be a waste of money.
It's worth noting that memory resilience features require extra memory modules. They won't add to your available memory pool. Save these features for your servers that run mission-critical workloads.
Network Access
Be sure you have adequate bandwidth available.
Consider upgrading your network interface to a quad port NIC. You may even install a 10 GbE NIC if your workload demands justify it.
Common 1 GbE network interface cards just won't cut it. Get rid of them and set up more rigorous network access
11. Discuss and compare the pros and cons of different virtualization techniques in different levels
Advantages of Virtualization
Following are some of the most recognized advantages of Virtualization, which are explained in detail.
Using Virtualization for Efficient Hardware Utilization
Virtualization decreases costs by reducing the need for physical hardware systems. Virtual machines use efficient hardware, which lowers the quantities of hardware, associated maintenance costs and reduces the power along with cooling the demand. You can allocate memory, space and CPU in just a second, making you more self-independent from hardware vendors.
Using Virtualization to Increase Availability
Virtualization platforms offer a number of advanced features that are not found on physical servers, which increase uptime and availability. Although the vendor feature names may be different, they usually offer capabilities such as live migration, storage migration, fault tolerance, high availability and distributed resource scheduling. These technologies keep virtual machines chugging along or give them the ability to recover from unplanned outages.
The ability to move a virtual machine from one server to another is perhaps one of the greatest single benefits of virtualization with far reaching uses. As the technology continues to mature to the point where it can do long-distance migrations, such as being able to move a virtual machine from one data center to another no matter the network latency involved.
Disaster Recovery
Disaster recovery is very easy when your servers are virtualized. With up-to-date snapshots of your virtual machines, you can quickly get back up and running. An organization can more easily create an affordable replication site. If a disaster strikes in the data center or server room itself, you can always move those virtual machines elsewhere into a cloud provider. Having that level of flexibility means your disaster recovery plan will be easier to enact and will have a 99% success rate.
Save Energy
Moving physical servers to virtual machines and consolidating them onto far fewer physical servers’ means lowering monthly power and cooling costs in the data center. It reduces carbon footprint and helps to clean up the air we breathe. Consumers want to see companies reducing their output of pollution and taking responsibility.
Deploying Servers too fast
You can quickly clone an image, master template or existing virtual machine to get a server up and running within minutes. You do not have to fill out purchase orders, wait for shipping and receiving and then rack, stack, and cable a physical machine only to spend additional hours waiting for the operating system and applications to complete their installations. With virtual backup tools like Veeam, redeploying images will be so fast that your end users will hardly notice there was an issue.
Save Space in your Server Room or Datacenter
Imagine a simple example: you have two racks with 30 physical servers and 4 switches. By virtualizing your servers, it will help you to reduce half the space used by the physical servers. The result can be two physical servers in a rack with one switch, where each physical server holds 15 virtualized servers.
Testing and setting up Lab Environment
While you are testing or installing something on your servers and it crashes, do not panic, as there is no data loss. Just revert to a previous snapshot and you can move forward as if the mistake did not even happen. You can also isolate these testing environments from end users while still keeping them online. When you have completely done your work, deploy it in live.
Shifting all your Local Infrastructure to Cloud in a day
If you decide to shift your entire virtualized infrastructure into a cloud provider, you can do it in a day. All the hypervisors offer you tools to export your virtual servers.
Possibility to Divide Services
If you have a single server, holding different applications this can increase the possibility of the services to crash with each other and increasing the fail rate of the server. If you virtualize this server, you can put applications in separated environments from each other as we have discussed previously.
Disadvantages of Virtualization
Although you cannot find many disadvantages for virtualization, we will discuss a few prominent ones as follows −
Extra Costs
Maybe you have to invest in the virtualization software and possibly additional hardware might be required to make the virtualization possible. This depends on your existing network. Many businesses have sufficient capacity to accommodate the virtualization without requiring much cash. If you have an infrastructure that is more than five years old, you have to consider an initial renewal budget.
Software Licensing
This is becoming less of a problem as more software vendors adapt to the increased adoption of virtualization. However, it is important to check with your vendors to understand how they view software use in a virtualized environment.
Learn the new Infrastructure
Implementing and managing a virtualized environment will require IT staff with expertise in virtualization. On the user side, a typical virtual environment will operate similarly to the non-virtual environment. There are some applications that do not adapt well to the virtualized environment.
12. Identify popular implementations and available tools for each level of visualization
1. VMware vSphere / ESXi.
2. Microsoft Windows Server 2012 Hyper-V (or the free Hyper-V Server 2012)
2. Microsoft Windows Server 2012 Hyper-V (or the free Hyper-V Server 2012)
3. Xen / Citrix XenServer.
4. Red Hat Enterprise Virtualization (
5. KVM.
13. What is the hypervisor and what is the role of it?
A hypervisor is a hardware virtualization technique that allows multiple guest operating systems (OS) to run on a single host system at the same time. The guest OS shares the hardware of the host computer, such that each OS appears to have its own processor, memory and other hardware resources.
A hypervisor is also known as a virtual machine manager (VMM).
The term hypervisor was first coined in 1956 by IBM to refer to software programs distributed with IBM RPQ for the IBM 360/65. The hypervisor program installed on the computer allowed the sharing of its memory.
The hypervisor installed on the server hardware controls the guest operating system running on the host machine. Its main job is to cater to the needs of the guest operating system and effectively manage it such that the instances of multiple operating systems do not interrupt one another.
Hypervisors can be divided into two types:
- Type 1: Also known as native or bare-metal hypervisors, these run directly on the host computer’s hardware to control the hardware resources and to manage guest operating systems. Examples of Type 1 hypervisors include VMware ESXi, Citrix XenServer and Microsoft Hyper-V hypervisor.
- Type 2: Also known as hosted hypervisors, these run within a formal operating system environment. In this type, the hypervisor runs as a distinct second layer while the operating system runs as a third layer above the hardware.
14. How does the emulation is different from VMs?
Virtual machines make use of CPU self-virtualization, to whatever extent it exists, to provide a virtualized interface to the real hardware. Emulators emulate hardware without relying on the CPU being able to run code directly and redirect some operations to a hypervisor controlling the virtual container.
A specific x86 example might help: Bochs is an emulator, emulating an entire processor in software even when it's running on a compatible physical processor; qemu is also an emulator, although with the use of a kernel-side
kqemu package it gained some limited virtualization capability when the emulated machine matched the physical hardware — but it could not really take advantage of full x86 self-virtualization, so it was a limited hypervisor; kvm is a virtual machine hypervisor.
A hypervisor could be said to "emulate" protected access; it doesn't emulate the processor, though, and it would be more correct to say that it mediates protected access.
Protected access means things like setting up page tables or reading/writing I/O ports. For the former, a hypervisor validates (and usually modifies, to match the hypervisor's own memory) the page table operation and performs the protected instruction itself; I/O operations are mapped to emulated device hardware instead of emulated CPU.
And just to complicate things, Wine is also more a hypervisor/virtual machine (albeit at a higher ABI level) than an emulator (hence "Wine Is Not an Emulator").
15. Compare and contrast the VMs and containers/dockers, indicating their advantages and disadvantages
What Are Virtual Machines (VMs)?

Historically, as server processing power and capacity increased, bare metal applications weren’t able to exploit the new abundance in resources. Thus, VMs were born, designed by running software on top of physical servers to emulate a particular hardware system. A hypervisor, or a virtual machine monitor, is software, firmware, or hardware that creates and runs VMs. It’s what sits between the hardware and the virtual machine and is necessary to virtualize the server.
Within each virtual machine runs a unique guest operating system. VMs with different operating systems can run on the same physical server—a UNIX VM can sit alongside a Linux VM, and so on. Each VM has its own binaries, libraries, and applications that it services, and the VM may be many gigabytes in size.
Server virtualization provided a variety of benefits, one of the biggest being the ability to consolidate applications onto a single system. Gone were the days of a single application running on a single server. Virtualization ushered in cost savings through reduced footprint, faster server provisioning, and improved disaster recovery (DR), because the DR site hardware no longer had to mirror the primary data center.
Development also benefited from this physical consolidation because greater utilization on larger, faster servers freed up subsequently unused servers to be repurposed for QA, development, or lab gear.
But this approach has had its drawbacks. Each VM includes a separate operating system image, which adds overhead in memory and storage footprint. As it turns out, this issue adds complexity to all stages of a software development lifecycle—from development and test to production and disaster recovery. This approach also severely limits the portability of applications between public clouds, private clouds, and traditional data centers.
What Are Containers?
Operating system (OS) virtualization has grown in popularity over the last decade to enable software to run predictably and well when moved from one server environment to another. But containers provide a way to run these isolated systems on a single server or host OS.
Containers sit on top of a physical server and its host OS—for example, Linux or Windows. Each container shares the host OS kernel and, usually, the binaries and libraries, too. Shared components are read-only. Containers are thus exceptionally “light”—they are only megabytes in size and take just seconds to start, versus gigabytes and minutes for a VM.
Containers also reduce management overhead. Because they share a common operating system, only a single operating system needs care and feeding for bug fixes, patches, and so on. This concept is similar to what we experience with hypervisor hosts: fewer management points but slightly higher fault domain. In short, containers are lighter weight and more portable than VMs.

{kind=link}
Comments
Post a Comment